
# 평균검정에 사용되는 t분포와 t검정

# 평균검정은 평균에 대한 가설검정을 의미
- 선정표본이 특정 평균값을 갖는 모집단에 속하는지(즉, 표본 평균과 모집단 평균이 동일한지) 여부나
- 두 표본집단 평균값 간에 차이가 존재하는지(즉, 두 표본집단이 동일 모집단에 속하는지)의 여부 검정
# 평균검정 방법: 일표본 평균검정, 독립표본 평균검정, 대응표본 평균검정
- 한 개 표본 있을 경우: 한 개 표본 있을 경우, 그 표본의 평균과 모집단의 평균이 동일한지 여부를 일표본 평균검정으로 검정
- 두 개 표본 있을 경우: 두 개 표본 있을 경우, 두 표본집단이 동일 모집단에 속하는지 여부 검정. 두 표본집단이 같은 평균값을 갖고 있는지 여부는 표본 선정 방법에 따라 1) 독립표본 평균검정과 2) 대응표본 평균검정을 이용해 검정할 수 있음

# t검정 설명
- 평균에 대한 가설검정은 t검정을 통해서 수행할 수 있음
- t검정을 이용해 검정하기 위해 검정통계량으로써 t값을 계산해야 함
- 표본평균과 모집단평균 동일 여부 검정을 위해 사용되는 t값 계산식은 위 그림과 같음
- 표본평균과 모집단평균 차이를 표본평균의 표준편차인 표준오차로 나눠서 구함
- 표준오차는 표본의 표준편차를 표본크기의 루트 값으로 나눠서 계산할 수 있음
- 표본평균과 모집단평균 동일 여부 검정을 위해 사용되는 t값 계산식은 위 그림과 같음
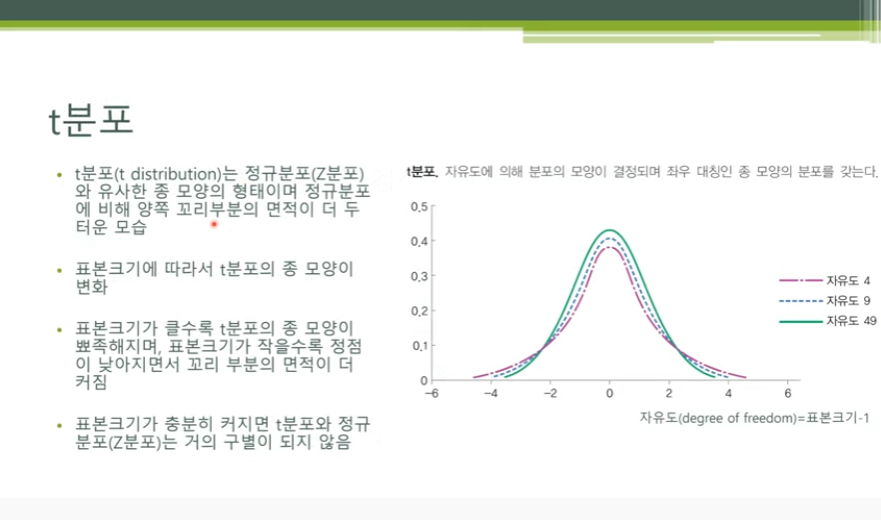
# t분포 설명
- 이렇게 계산되는 t값은 t분포를 따름
- t분포는 정규분포와 유사한 종 모양 형태를 가짐
- 표본크기에 따라서 모양이 달라짐
- 표본크기가 작은 경우가 큰 경우보다 변동성이 더 큰 분포를 보이고, 상대적으로 정점이 낮고 양쪽 꼬리 부분이 더 두툼해서 퍼져 있는 모습
- 위 그림 t분포 그래프에서 표본크기에 따라, t분포의 종 모양이 변화함
- 표본크기가 클수록 t분포의 종 모양이 뾰족해지는 것을 볼 수 있고
- 표본크기가 작아질수록 정점이 낮아지면서 꼬리 부분이 면적이 두터워짐
- 표본크기가 충분히 커지면 t분포와 정규분포는 거의 구별되지 않음

# t검정을 수행절차 (예제: 벤처 기업 경영자의 평균 혈압이 일반인과 다른지? )
- 대립가설: "벤처 기업 경영자의 혈압은 일반인과 다르다"
- 귀무가설: "벤처 기업 경영자의 혈압은 일반인과 같다"
- 표본: 대립가설 검정위한 무작위 선정 20명 벤처 기업 경영자 혈압 측정 후 평균 135, 표준편차 25인 관측값 얻음
- 모집단: 모집단 대응 일반인 혈압 평균이 115로 알려져 있음
- "일반인과 다르다"이기 때문에 상대적으로 높은 혈압과 낮은 혈압이라는 양쪽 가능성 모두 고려한 양측검정을 수행함
- 양측검정
- 대립가설이 "벤처 기업 경영자의 혈압은 일반인과 다르다"이기 때문에, 이런 정보를 바탕으로 해서 벤처 기업 경영자의 혈압이 일반 사람과 다르다는 주장 검정 가능
- 만약 표본으로부터 얻은 표본평균이 115보다 상대적으로 크거나 115보다 상대적으로 작은 경우에는 모두 대립가설의 주장을 지지하는 증거로 사용될 수 있어,
- 표본평균이 일반인 혈압 분포하에서 얼마나 드문지 혹은 얼마나 흔한지 평가할 때 상대적으로 높은 혈압과 상대적으로 낮은 혈압이 나타날 가능성을 모두 고려해야 함
- 이렇게 양쪽의 가능성을 모두 고려한다고 해서 이런 형태의 가설검정을 양측검정이라고 함
- 단측검정
- 반면 단측검정은 대립가설이 "벤처 기업 경영자의 혈압은 일반인보다 높다" 혹은 "일반인보다 낮다" 이런 식으로 표현됨
- 그래서 이럴 때는 높다, 낮다의 다양성이 있기 때문에 그런 한쪽이 발생할 가능성만을 고려하게 됨
- 양측검정
- t값 계산: 가설검정 위해 먼저 검정통계량 t값 계산해야 함. 그림과 같이 표본평균과 모집단평균의 차이를 표본평균의 표준편차인 표준오차로 나눠서 계산함
- 이렇게 표본으로부터 얻은 t값이, 귀무가설이 사실이란 전제하에서, 얼마나 흔히 관찰될 수 있는 것인지 혹은 얼마나 드물게 관찰될 수 있는 것인지를 평가해 그걸 통해 가설검정을 수행할 수 있음
- 귀무가설이 사실이란 전제하에서 만들어지는 t분포를 그려보고 그 t분포 상에서 계산된 3.58이 발생할 가능성이 얼마나 높은지, 낮은지를 그래프로 표현함
- 위 그림 설명
- 가운데가 t가 0이고 대칭인 t분포
- t가 0인 이 지점은 실제 혈압으로 표현한다면 모집단의 평균인 115에 대응됨
- 표본으로부터 얻은 135로부터 계산된 t값 3.58은 t=0이 가운데에 있기 때문에 오른쪽 끝부분에 위치
- 이 3.58 혹은 그 이상이 발생할 확률이 얼마인지가 궁금한 것임
- 이 3.58에 대응되는 실제 혈압은 표본으로부터 계산된 135가 되고, 그래서 모집단 혈압 평균이 115라는 가정하에서 135 이상의 혈압이 발생할 확률을 계산해서 그것이 0.05보다 작으면 유의수준 5%에서 귀무가설을 기각하고 대립가설을 채택할 수 있음, 즉, "벤처 기업 경영자의 혈압은 일반인보다 크다"라고 얘기할 수가 있음 ***즉, 표본의 혈압인 135이 일반적으로는 잘 나타나지 않아 5% 이하로 나타나기에, 벤처 기업 경영자와 일반인 혈압 간 차이가 없다는 귀무가설 기각***
- 근데 우리의 대립가설은 "벤처 기업 경영자의 혈압이 일반인보다 크다"가 아닌 "벤처기업 경영자의 혈압은 일반인과 다르다" 임. 즉, 다르다는 것은 왼편도 이 작은 부분도 같이 고려해야 하기 때문에 3.58에 대칭되는 -3.58 이하 발생확률도 함께 고려해야 함
- 3.58이 115로부터 20만큼 떨어진 부분이기 때문에, -3.58에 대응되는 실제 혈압은 95. 그래서 "벤처 기업 경영자의 혈압이 일반인과 다르다"라는 대립가설 채택 여부는 빨간색으로 빗금 쳐 있는 이 두 부분의 확률이 얼마나 드문지 혹은 흔한지를 가지고 평가하게 됨
- 이 두 부분의 확률값이 P라고 했을 때, P가 0.05보다 작은지를 평가해서 만약 0.05보다 작으면 모집단의 혈압 평균이 115라는 가정하에서는 굉장히 드문 현상이 관찰된 것이기 때문에 귀무가설을 기각하고 대립가설을 채택. "벤처 기업 경영자의 혈압은 일반인과 다르다"라고 결론 내림
- 그래서 3.58 이상이 발생할 확률과 -3.58 이하가 발생할 확률을 계산해야 함
- 3.58 이상이 발생할 확률과 -3.58 이하가 발생할 확률 계산
https://youtu.be/srH9ru9DhnU?list=PLY0OaF78qqGAxKX91WuRigHpwBU0C2SB_&t=561
#05.통계데이터분석 - 평균검정 - t검정 🔑 t test | t값(t value) | t분포(t distribution) | 신뢰구간(confidence interval)
# https://www.youtube.com/watch?v=srH9ru9DhnU&list=PLY0OaF78qqGAxKX91WuRigHpwBU0C2SB_&index=6
### t분포에서 특정 t값에 대응되는 누적확률을 계산할 수 있는 확률분포함수
# https://youtu.be/srH9ru9DhnU?t=562
## pt함수
# 가설검정 방법1: pt함수로 t분포에서 특정 t값에 대응되는 누적 확률을 계산가능. 이렇게 누적확률을 계산하게 되면 이를 이용해 유의확률도 구할 수 있음
pt(3.58, df=20-1) # 3.58 이하의 누적확률이 계산됨
# [1] 0.9990014
# 1st인수 : T값 지정
# 2nd인수 : df인수로로 자유도 지정(자유도는 표본크기에서 1을 뺀 값으로 정의됨)
# 지금 관심 있는 것은 그 반대편 확률이기 때문에 lower.tail 인수를 FALSE로 지정해 3.58 이상의 확률을 계산함
pt(3.58, df=20-1, lower.tail=FALSE) # 계산된 값은 3.58 이상의 확률이 계산됨
# [1] 0.0009986368
# 반대편의 확률, 즉, -3.58 이하 확률도 계산해야 하기 때문에 이것에 두 배를 한 값이 우리가 원하는 유의확률이 됨
pt(3.58, df=20-1, lower.tail=FALSE) * 2 # 계산된 값은 3.58 이상의 확률이 계산됨
# [1] 0.001997274
# 해석: 약 0.002로 유의수준 0.05에 비해 굉장히 작아 굉장히 드문 현상이 관찰된 것임. 모집단 평균이 115라는 전제하에 135 이상 혹 95 이하 혈압 발생 가능성이 0.002에 불과해 "벤처 기업 경영자의 혈압은 일반 사람들과 같다"라는 귀무가설 기각하고 대립가설을 채택하게 됨
## qt함수
# 가설검정 방법2:qt함수 이용시, 특정 확률에 대응되는 t값 산출 가능
# 유의수준 0.05에 대응되는 t값 구한 후 표본으로부터 계산돼 관측된 t값과 비교. 양측검정 시, 관측된 t값이 유의수준에 대응되는 t값보다 t분포 상 더 바깥쪽에 있으면, 즉, 절댓값으로 비교해서 크면 귀무가설을 기각하게 됨
# 아래 t분포 그림 설명
# 아래 t분포 그림으로 살펴보면, 유의수준 0.05에 대응되는 t값이 양쪽 끝부분 면적 합이 0.05가 되는 t값을 의미함
# 양쪽 끝부분의 합이 0.05라는 것은 각각 0.025를 의미함
# 아래 t분포 그림 양쪽 끝부분 면적이 0.025 되는 부분에 대응되는 t값 산출 후 표본으로부터 계산된 3.58이 면적이 0.025되는 부분 경계선의 바깥쪽에 있는지 혹은 안쪽에 있는지를 확인함
# 이 경계선 바깥쪽에 있다면 관측한 t값 발생가능성이 유의수준 0.05에 비해 작다는 의미이기에, 귀무가설 기각하고 대립가설 채택
qt(0.025, df=20-1) # 왼쪽 부분 면적이 0.025에 대응되는 t값 산출
# [1] -2.093024
# 1st인수 : 확률 지정(여기서는 0.025)
# 2nd인수 : df인수로로 자유도 지정
# 지금 관심 있는 것은 그 반대편 확률이기 때문에 lower.tail 인수를 FALSE로 지정해 0.025이상의 확률을 계산함
# 우리가 원하는 것은 왼쪽이 아닌 오른쪽 끝부분의 면적이 0.025에 대응되는 t값을 계산하는 것이기에 lower.tail 인수에 FALSE 지정
qt(0.025, df=20-1, lower.tail=FALSE) # 왼쪽 부분 면적이 0.025에 대응되는 t값 산출
# [1] 2.093024
# 해석1: 결과값인 2.09는 오른쪽 끝부분 면적이 0.025에 대응되는 t값이며, 왼쪽 끝부분 면적이 0.025에 대응되는 t값은 -2.09가 됨. 3.58은 2.09 바깥쪽에 있고 -3.58도은 -2.09 바깥쪽에 있기 때문에 표본으로부터 관측된 t값을 굉장히 드문 현상으로 인식할 수 있음.
# 해석2: 0.025에 대응되는 t값이 2.09와 -2.09고 표본으로부터 관측된 t값이 3.58과 -3.58이기 때문에 절댓값으로 비교해서 관측된 t값이 유의수준 0.05에 대응되는 t값보다 크기 때문에, 즉, 굉장히 드문 현상이 관측된 것이기 때문에 귀무가설 기각하고 대립가설 채택해 "벤처 기업 경영자의 혈압은 일반인과 다르다"라고 결론# 아래 그림에 대한 설명은 위의 R코드 주석에 설명됨

# 위 R코드를 통해 얻은 t검정 결과에 비춰 볼 때, 벤처 기업 경영자의 평균 혈압은 일반 사람의 평균 혈압인 115라고 얘기할 만한 통계적 근거가 없다는 것을 알게 됨
# 하지만 그렇다고 해서 표본에 의해 계산된 평균 혈압 135가 벤처 기업 경영자 모집단의 평균이라 얘기하는 것 역시 무리가 있음. 이 평균값은 표본마다 차이가 있을 것이기 때문임.
# 사실 벤처 기업 경영자 모집단의 실제 평균 혈압을 정확히 알 수는 없음. t분포의 특성을 이용하면 모집단평균의 가능한 범위를 예측 가능
# 모집단평균의 가능한 범위 예측
- 앞서 가설검정을 위해서 벤처 기업 경영자 20명을 선정하고 그로부터 평균 혈압 135를 구했음
- 이와 유사한 방식으로
- 벤처 기업 경영자 모집단으로부터 임의로 20명을 선정하는 작업을 반복해
- 혈압 평균을 구하고 이렇게 구한 혈압의 평균을 t값으로 환산하게 되면
- 이렇게 구해진 t값 가운데서 95%는 -2.09와 2.09의 범위 내에 존재하게 됨. 나머지 5%는 이 범위를 벗어나 양쪽 끝 꼬리 부분에 포함됨

- 이를 산식으로 표현하면 위 그림과 같음
- t값의 95%는 -2.09와 2.09 사이에 존재함(식1)
- t를 계산하는 공식은 이와 같기 때문에 t 대신에 이 산식을 집어넣게 되면 임의의 표본평균 가운데 95%는 이러한 범위에 속하게 됨(식2)
- 이 식을 다시 모집단평균에 대해서 정리하게 되면 모집단평균은 식3과 같은 범위에 속하게 됨

- 그래서 이러한 식을 이용하게 되면 임의의 표본으로부터 산출된 표본평균과 표준오차 정보를 바탕으로 95%의 믿음 하에서 모집단평균이 포함되는 범위를 계산할 수 있음
- 그래서 범위를 계산하게 되면 하한값은 표본평균에서 2.09배의 표준오차만큼 뺀 값이 되고 상한값은 반대로 표본평균에 2.09배의 표준오차를 더한 값이 됨(식2)
- 이 같은 범위를 모집단평균의 95% 신뢰구간이라 하고, 이렇게 구해진 모집단 평균의 95% 신뢰구간은 123.3부터 146.7까지가 됨(식3)

# 신뢰구간 내 모집단평균이 포함되는 경우와 포함되지 않는 경우의 예시설명
- 왼쪽의 경우는 95% 신뢰구간 내에 모집단평균이 포함되는 경우고, 오른쪽 경우는 95% 신뢰구간 내에 모집단평균이 포함되지 않는 경우임
- 왼쪽은 모집단의 평균은 표본의 평균으로부터 1.5배 표준오차만큼 떨어져 있고, 신뢰구간은 그보다 더 긴 두 배만큼 연장돼 있기 때문에 신뢰구간은 미지의 모집단평균을 포함함
- 오른쪽은 표본평균이 모집단평균에서 두 배의 표준오차를 초과하는 거리만큼 떨어져 있고, 모집단평균에 대한 95% 신뢰구간 내에 모집단평균이 포함되지 않고 있음
- 사실 선택된 표본의 평균이 미지의 모집단평균과 얼마만큼 차이가 나는지는 알 수 없기 때문에 우리가 도출한 신뢰구간이 모집단평균을 실제로 포함하는지의 여부는 알 수 없음. 하지만 선택된 표본으로부터 계산된 모집단평균에 대한 95% 신뢰구간을 이용해서 95% 신뢰구간이 모집단평균을 포함할 가능성은 100개의 표본 가운데서 95개일 것으로 예측해보는 것은 가능
- 즉, 100개의 표본으로부터 구한 신뢰구간 중 95개는 왼쪽 경우처럼 모집단의 평균을 포함하게 된다는 의미이기도 함. 이는 또한 100개의 표본 가운데 5개는 오른쪽과 같이 실제로 신뢰구간 내에 모집단의 평균을 포함하지 않게 된다는 것을 의미하기도 함